Mehmet Ergene
A Deep Dive into the KQL Union Operator
The
union operator in KQL is used to merge the results of two or more tables (or tabular expressions) into a single result set. A familiar instance of this operation is the search operator, which implicitly performs a union when querying across multiple tables.Syntax:
<Table1>
| union (<OptionalParameters>) <Table2>, <Table3>, <TabularExpression1>, ...
// We can also use the below syntax
union (<OptionalParameters>) <Table1>, <Table2>, <TabularExpression1>, ...
<TableN>: Name of the table to be included in the union.<TabularExpression>: A query that generates tabular results.<OptionalParameters>: (Optional) Modifiers to tailor the union operation, such askind=inner.
Optional Parameters for Union
kind Parameter
The
kind parameter in union operations dictates how the result set is structured in terms of column inclusion:- By default, union combines columns with the same names and data types into a single column. Columns without matches across all tables are still included in the result set and filled with nulls where applicable.
Example with default behavior:
union UserLoginEvents, UserProfiles
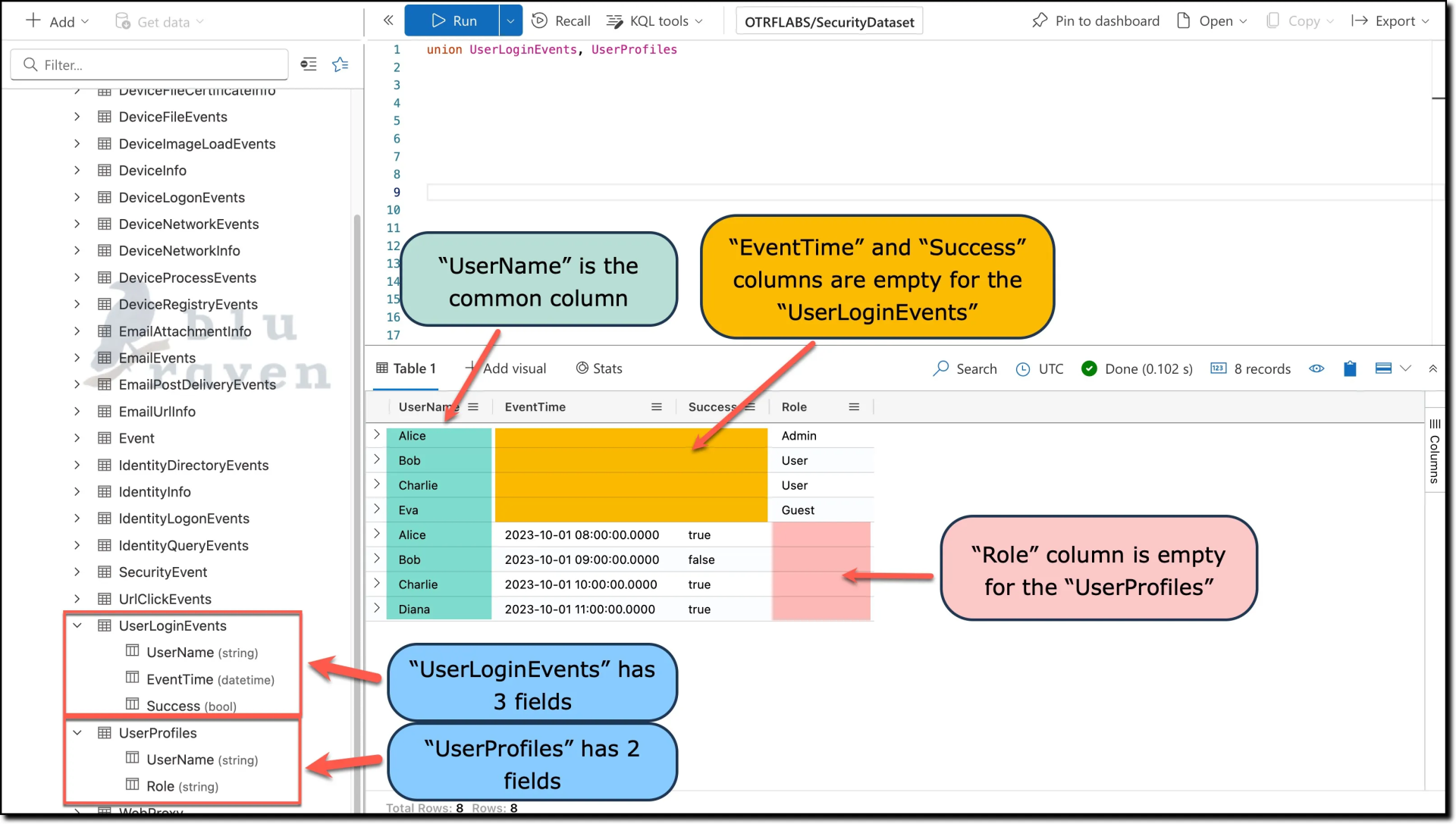
The
kind=inner modification alters this behavior. When applied, only the columns common to all participating tables are included in the result set, and non-matching columns are excluded.Example with kind=inner:
union kind=inner UserLoginEvents, UserProfiles
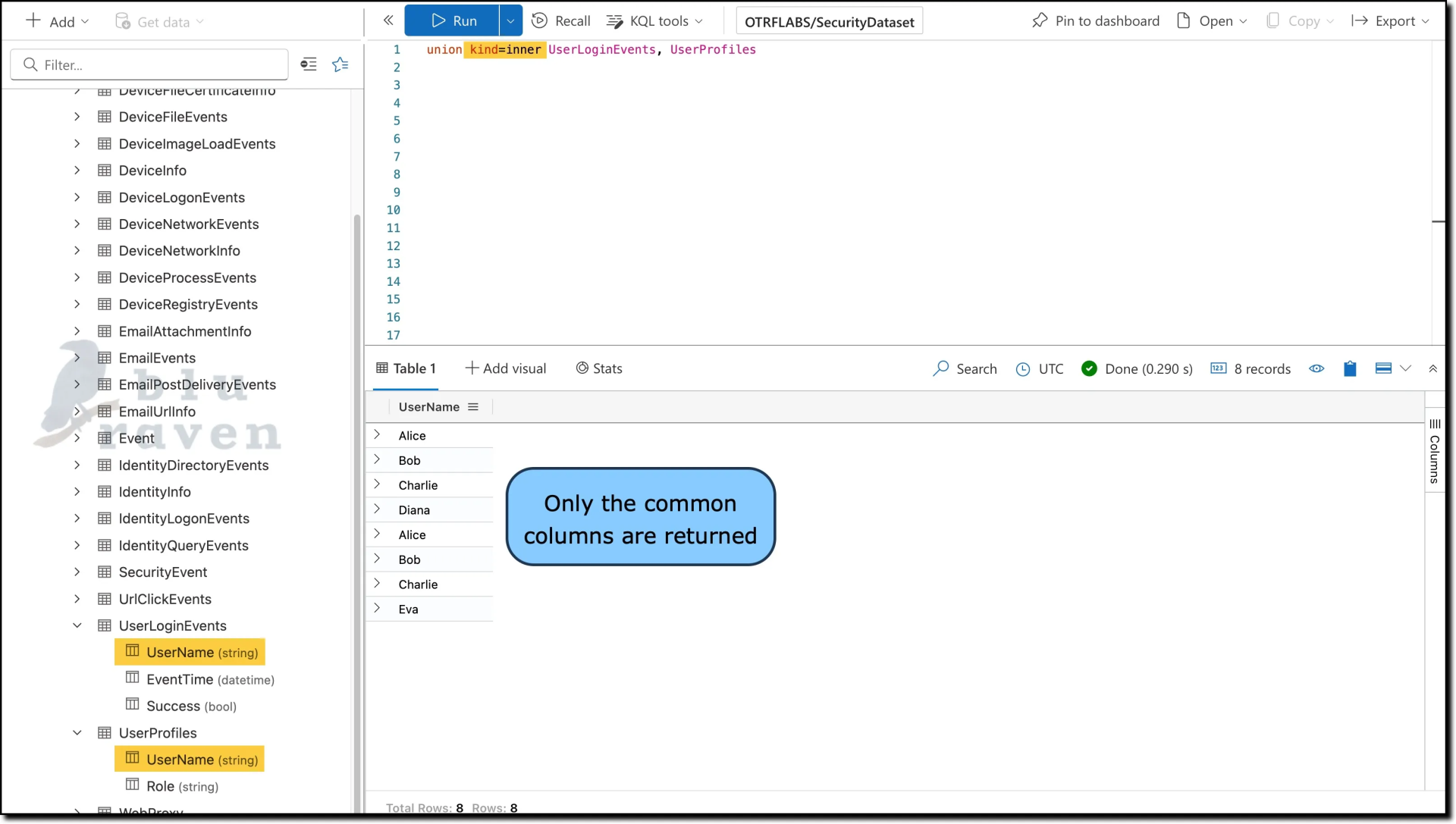
The
kind=inner option is particularly useful when you are interested in analyzing only the overlapping data between tables, providing a cleaner and more focused dataset.withsource Parameter
The
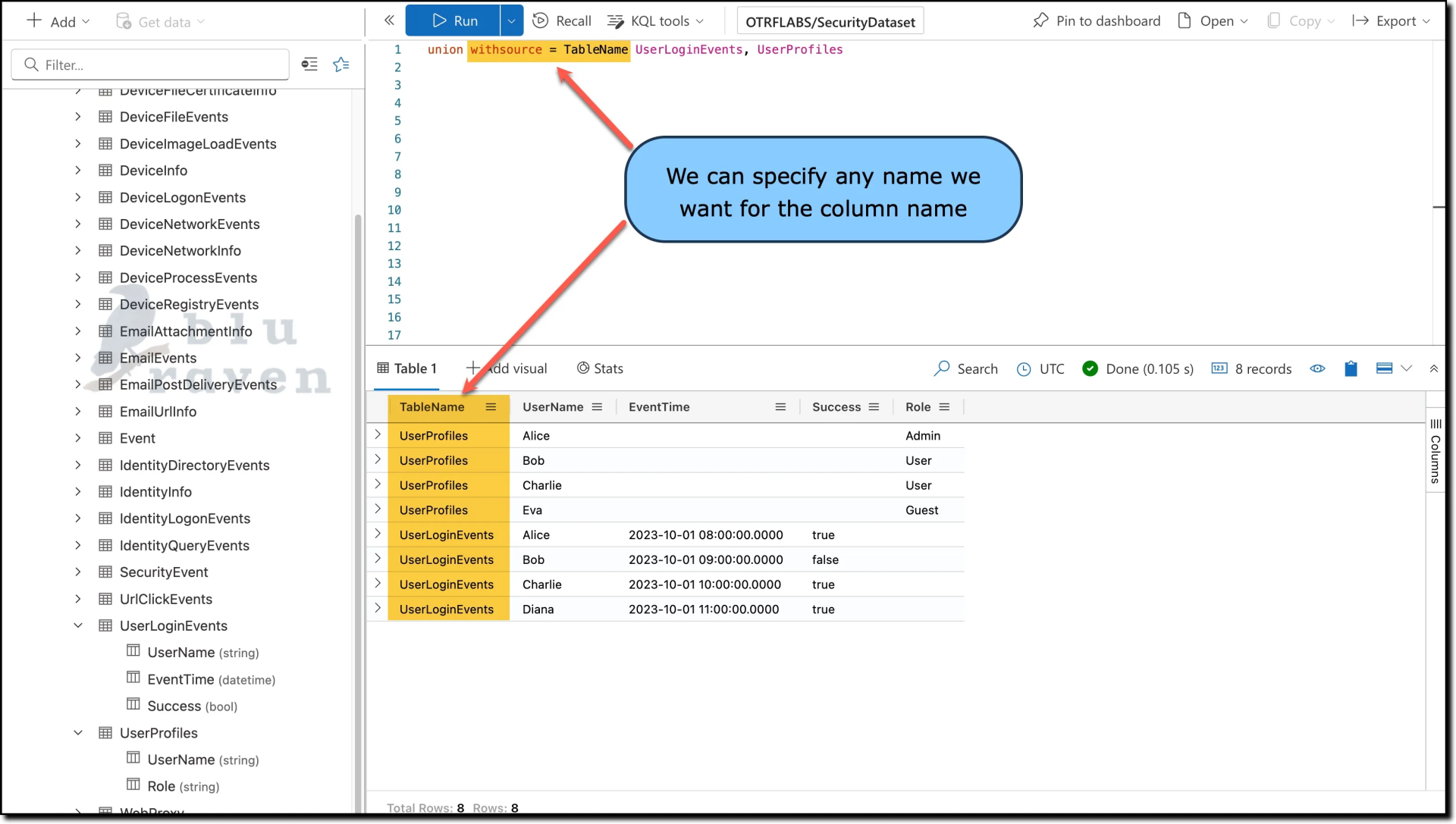
withsource parameter is beneficial when merging tables and you need to track the origin of each record:- The syntax
withsource = <ColumnName>adds a new column to the result set. This column is named according to the<ColumnName>provided and records the source table for each row.
Example using withsource:
union withsource = TableName UserLoginEvents, UserProfiles
isfuzzy Parameter
When combining data from multiple tables using union, the query will fail if any of the tables are inaccessible:
// This query fails because "InaccessibleTable" does not exist.
union UserLoginEvents, UserProfiles, InaccessibleTable
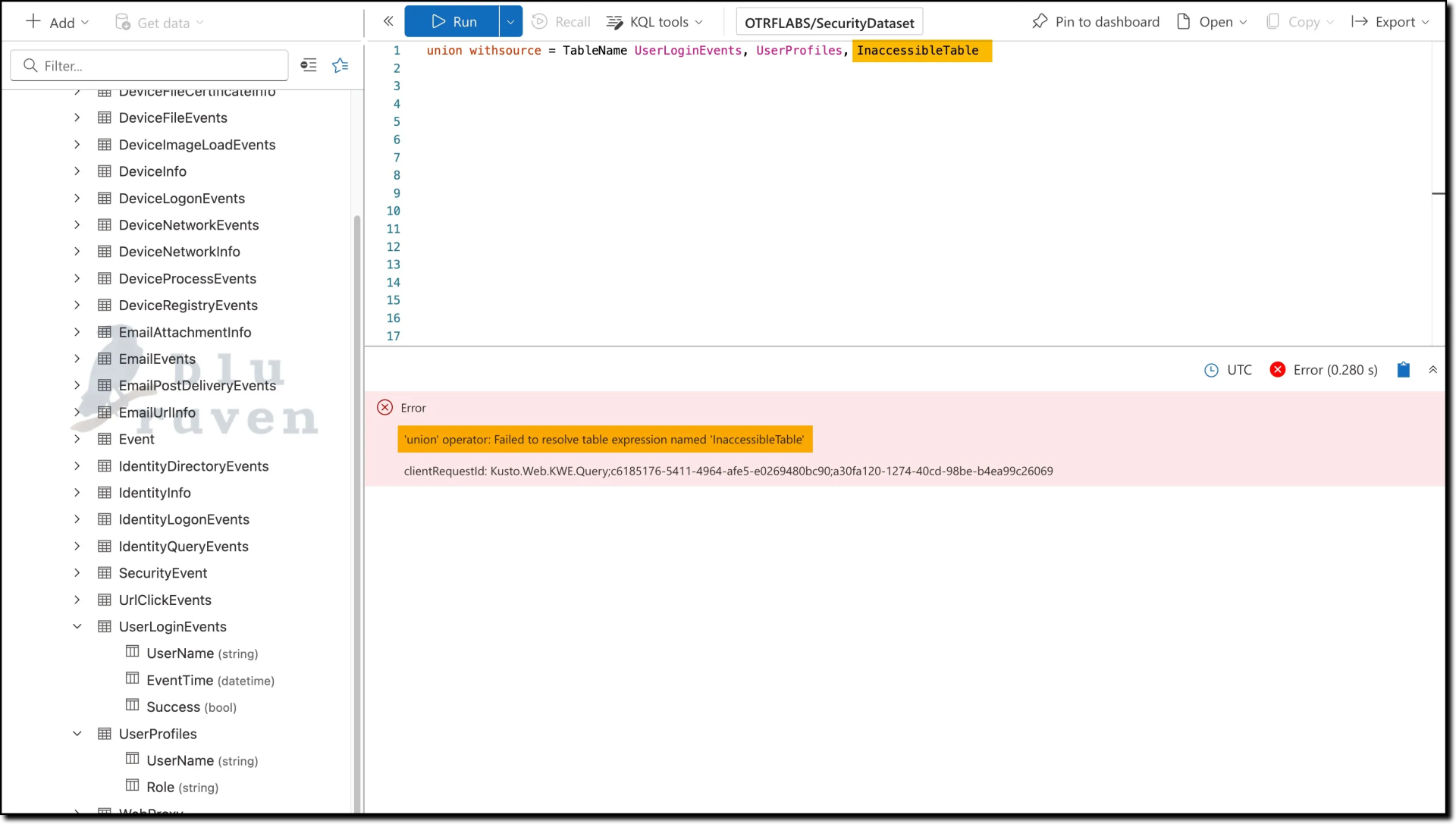
To prevent the entire query from failing due to one or more inaccessible tables, we can employ the
isfuzzy=true parameter. This parameter instructs the query to proceed with the accessible tables and ignore the ones that cannot be accessed:// This query succeeds, ignoring the missing "InaccessibleTable".
union isfuzzy=true UserLoginEvents, UserProfiles, InaccessibleTable
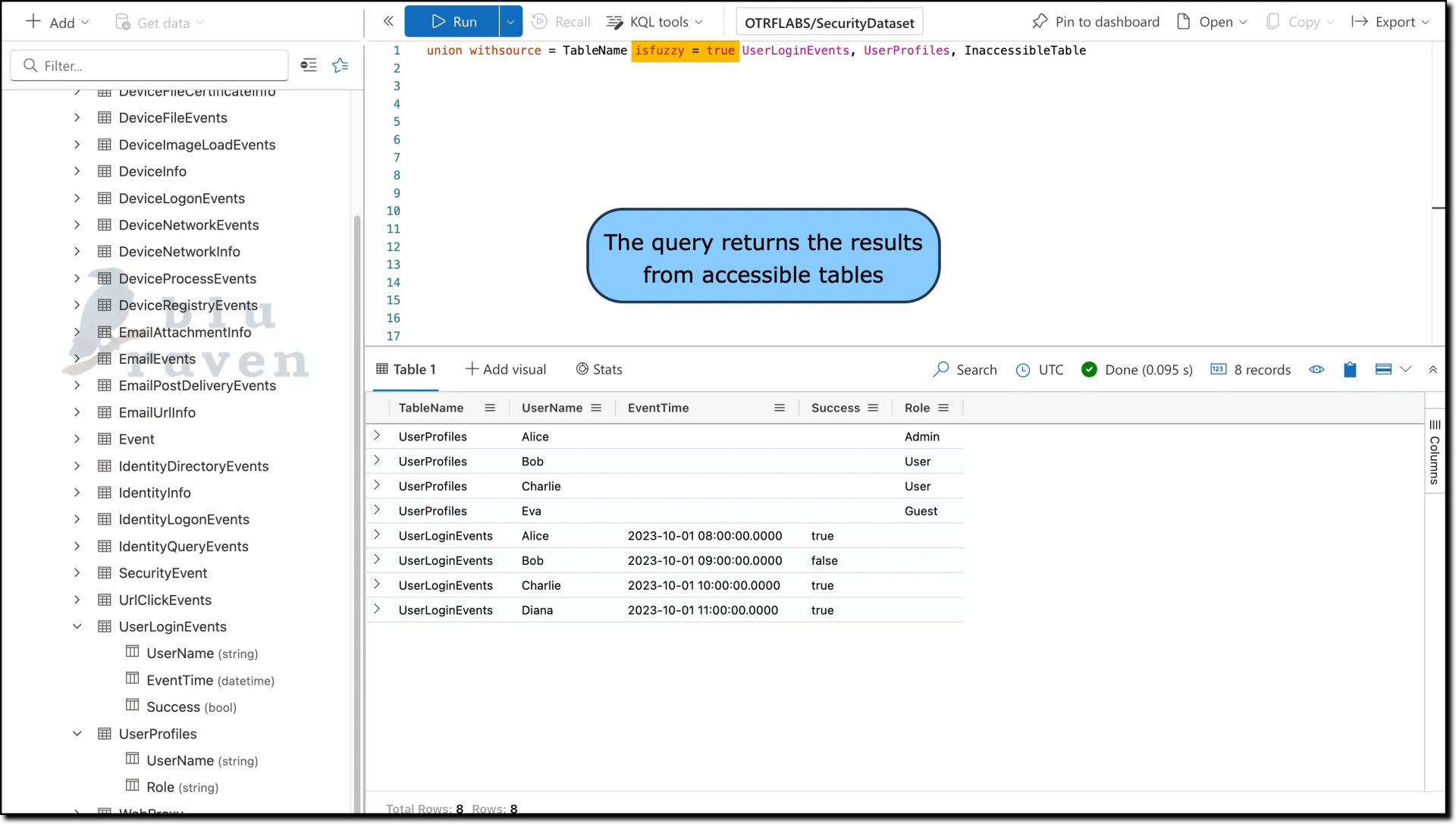
By using
isfuzzy=true, we ensure that our query still returns useful data, despite any issues with table accessibility, allowing for a more resilient and fault-tolerant data retrieval approach.Best Practices for the union Operator
Utilizing the
union operator in KQL can be a powerful way to synthesize data from multiple tables. However, when dealing with large datasets, the order of operations is crucial for query performance. A common mistake is to combine the tables into a union and then apply filters, which can be inefficient and time-consuming.For optimal performance, it’s recommended to filter each dataset before uniting them. This approach minimizes the amount of data being processed and can lead to significant gains in speed and efficiency.
Here’s how you can structure an efficient query:
union <OptionalParameters> (<TabularExpression1>), (<TabularExpression>), ...Each <TabularExpressionN> represents a query that performs necessary filtering on the data.
Consider the following examples that highlight inefficient and efficient approaches:
Inefficient query:
union isfuzzy = true DeviceProcessEvents, DeviceEvents
| where Timestamp > ago(5d)
| where AccountName =~ "alex.wilber"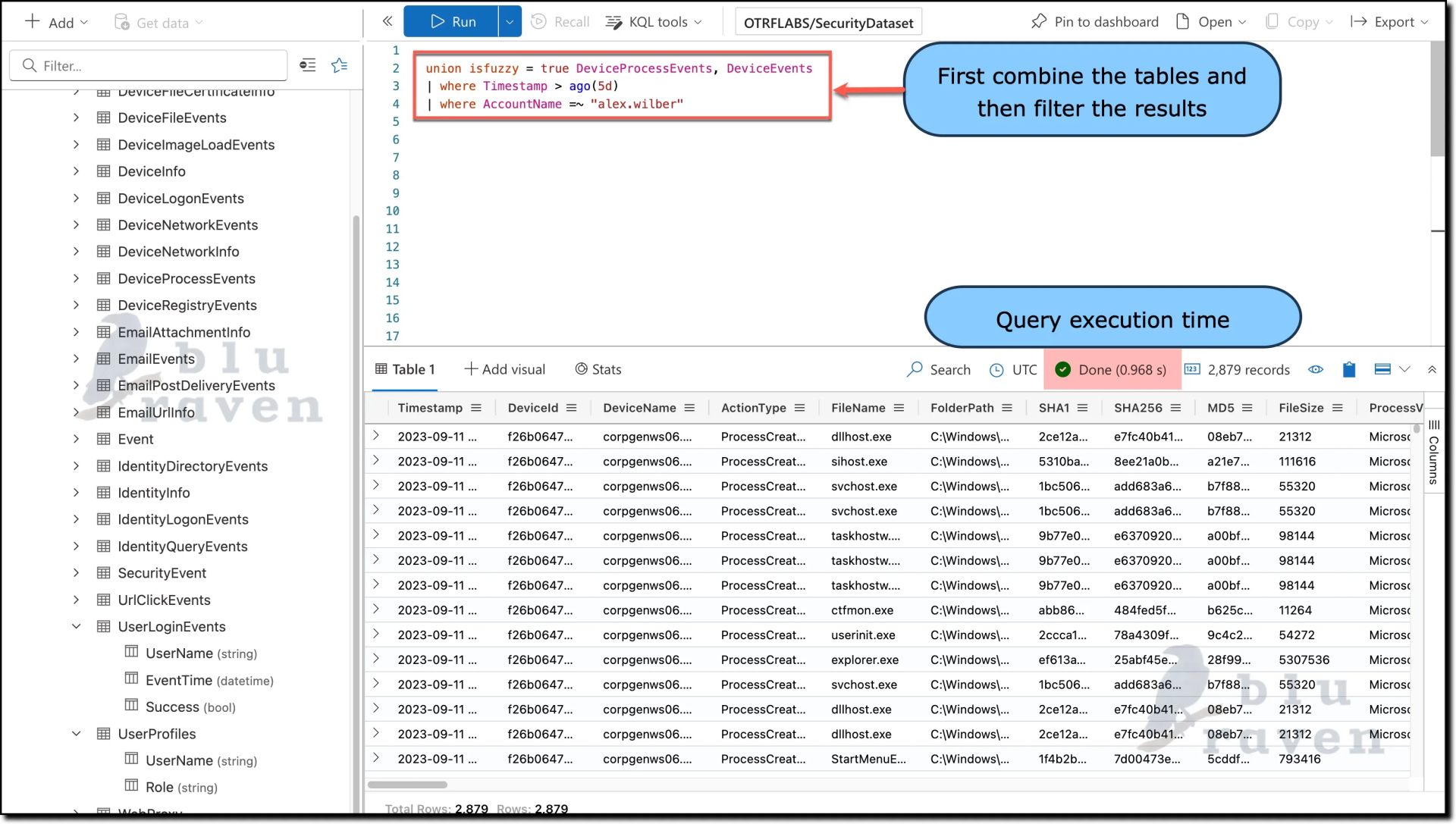
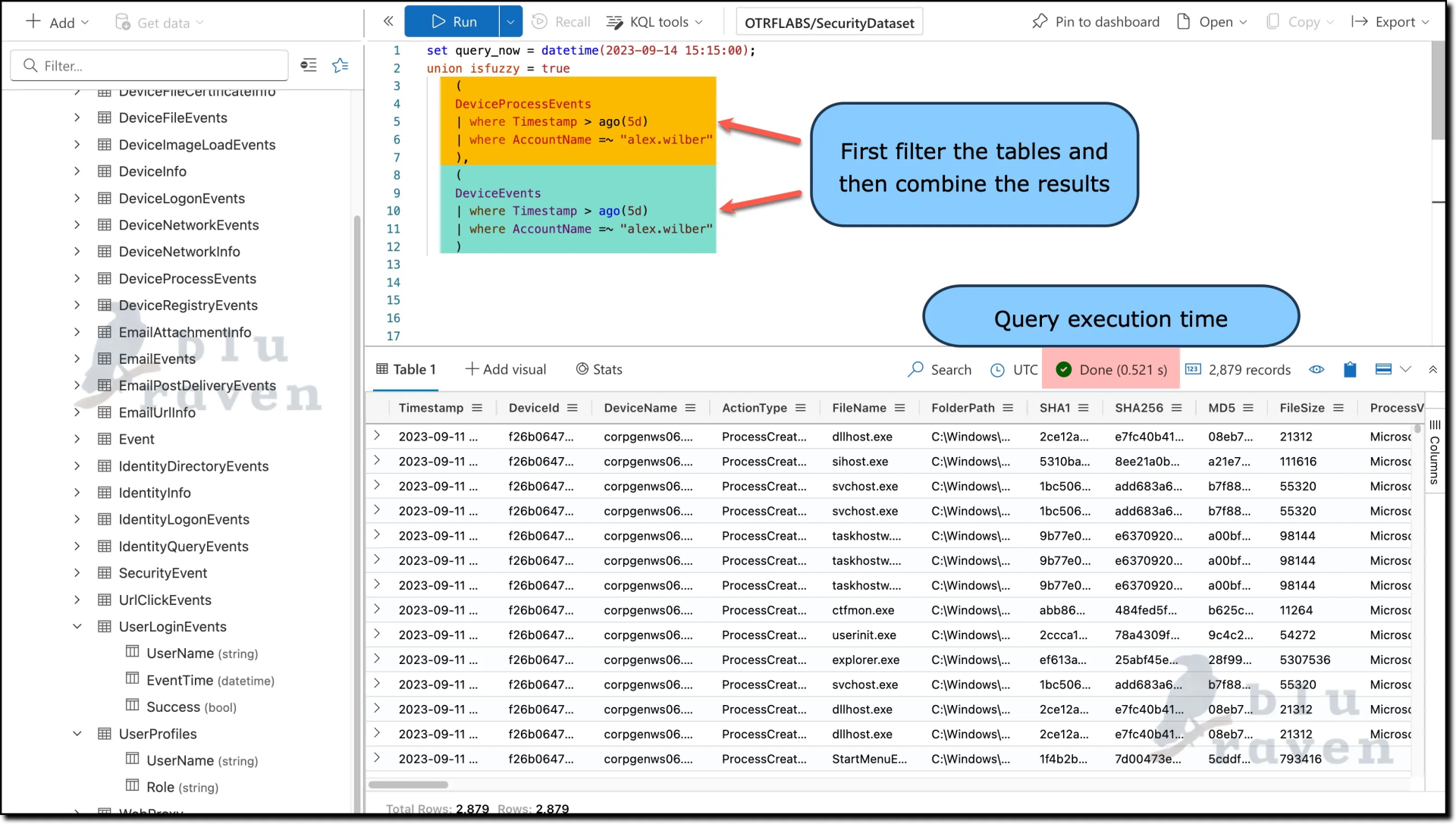
Efficient Query:
union isfuzzy = true
(
DeviceProcessEvents
| where Timestamp > ago(5d)
| where AccountName =~ "alex.wilber"
),
(
DeviceEvents
| where Timestamp > ago(5d)
| where AccountName =~ "alex.wilber"
)
In addition to pre-filtering data, it’s also worth considering alternatives to union when the situation calls for it. If your analysis requires comparing or correlating data between tables instead of combining their contents, the join operation may offer a more appropriate and efficient solution.
By embracing these best practices, you can ensure your queries are both performant and effective, an important consideration as datasets continue to expand in size.
Update on pre-filtering
According to the ADX team, the filters should be pushed into the union legs. There is also a StackOverflow post that says the filters are pushed into the union legs whenever possible. Seems like it depends on the columns used for filtering. Therefore, if your union query performs well without pre-filtering inside the union legs, you can keep it as it is. Otherwise, apply pre-filtering explicitly.
Share
Copyright © 2026
Featured Links
Subscribe to our Newsletter!
Thank you!
New Challenge Lab
We're excited to launch our first hands-on lab challenge: Threat Hunting and Incident Response Case #001!
This lab simulates a real-world breach with two investigation paths:
This lab simulates a real-world breach with two investigation paths:
1️⃣ Incident Response: Triage an initial alert and unfold the attack.
2️⃣ Threat Hunting: Start with a TTP and hunt for adversary activity.
Select your country
Please choose your country to see the correct page.